
Azure Event Hubs with Stream Analytics is a powerful combination for quasi real time high throughput data processing.
It’s a great solution if you want fast reporting on live data and save your architecture from extra complexity.
Use case: Your service receives real time high volume user data I.E. website tracking or application telemetry or IoT.
The traditional process for generating reports would involve slow and painful steps such as:
- Sensors/source sending data to a queue
- Service A constantly fetching messages from the queue
- Service A storing data
- Service B querying the data persistence layer
- Service B processing/aggregating the data
- Service B storing the result of the processor
And, of course, the process involves development resources for the implementation and several machine resources.
The solution: Event Hub, Stream Analytics, Service Bus

This can be simplified by letting Azure take care of most of the steps:
- Sensors sending data to Event Hub
- Stream Analytics aggregating/processing the data in time windows and storing the result or handing it over to a service.
In diagram the result is sent to a Service Bus queue to be stored/processed by a service later, but Stream Analytics has the capability of storing directly to many data layers.
Event Hub is a chronological stream storage, there is no concept of message locking or deletion and stores data in partitions allowing parallel access for multiple consumers. We don’t have to worry about removing messages once processed as our progress can be stored into checkpoints which record the point in time where we stopped processing to resume later.
Data is safely stored there and resilient and it will only be deleted after it passed the expiration set in the retention option, no manual/accidental deletion.
The architecture described in the diagram is the cheapest and simplest but it doesn’t take into account high availability; if the Azure Event Hub in our region has an outage we will lose all the messages during that period.
We can setup a failover stream in a different region to accept messages in case the primary hub is unavailable:
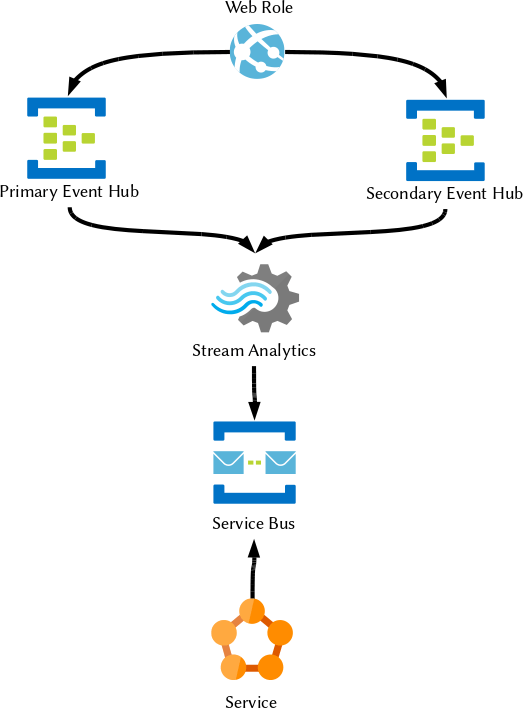
In this example our web application has to implement a failover logic to try and send messages to the primary and failover to the secondary during downtimes (I.E. in case of exceptions on sends).
We now have a good solution to prevent data loss from the web application side as the event will find its way in one or another hub and, assuming we set up the secondary in a different Azure region, we achieved geo-redundancy and we also qualify for the Azure 99.9% SLA making our messages resilient to alien invasions (I do not take responsibility if they target your two Azure clusters specifically).
Is it over? Are we happy our customers will never contact our support again? Of course not…
What happens then if the Stream Analytics service has an outage? Messages will be safe and sound but their journey will be delayed for the duration of the outage.
It is true that looking at the history of outages there has never been one involving Stream Analyitics, but we cannot rely on hope when it comes to the danger of pissing off customers.
Let’s try and solve this, too. On a Microsoft blog, the recommended solution is similar to the following:

Now we have a geo-redundancy of all the resources, but what happens when one Stream Analytics only has an outage? It’s unlikely that the whole region will be down, and we have no guarantee the services will be in the same fault/update domain. It might only happen in case a bomb lands on the whole data centre set, but in that eventuality we have bigger fish to fries so let’s go back to it later.
If only Stream Analytics is down, the primary Event Hub and our web application will be unaware and will continue to store messages in the stream that will not be processed down in the chain; we will be unaware until we hear customer shouting.
We need to make sure a Stream Analytics works as failover and we could do so by checking the status of the service before sending messages… but:
- There is no public Azure API to check the status of the service
- Our high throughput and performance critical application receiving millions of requests would have to delay the completion to make a new check request to a service on every call.
So, even if we had the API, it would not be the best way to go. Maybe a separate background service checking the status, but we still risk of losing messages in the delay for our service to give us the status after the real outage occurred.
So let’s try something else:
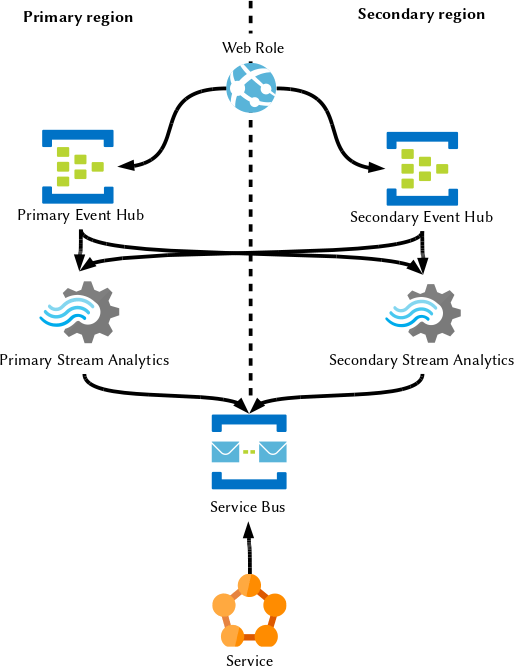
But now, both the SA will process the same messages and generate an output which is likely to be similar, but extremely unlikely to be exactly the same (Resources contention, time windows unaligned, et cetera).
This is still a good solution if you do not care about having potential duplicates in the data.
But if this is not your case, how do we know what’s in the primary and what’s in the secondary? How do we avoid duplication?
At the time I’m writing this there is no solution.
Event Hubs works with checkpoints and Stream Analytics stores its checkpoint somewere and a good solution would be to share checkpoints across the two Stream Analytics as they will work in synergy and never overlap each other; but Azure does not support this feature at the moment.
So we go back to this original solution if we care about the precision of our data and we have to hope the weak ring (Stream Analytics) will not fail (which is unlikely as it is also based on Service Fabric.
I will stress the fact that we never lose data in this configuration so we might only delay the processing for the duration of the outage:
But yet we have another problem… What happens when the output Service Bus is down? I verified empirically that Stream Analytics has an internal cache for messages, but there is no guarantee the message will land eventually and the retention can be days, minutes or seconds (source:Microsoft). So we can send message identical copies to two geo-redundant Service Bus queues to prevent loss.
We would also like our services not to process twice the same message though, so what can we do?
My first idea was to add a unique identifier to the messages so our service can cache it and make sure it doesn’t process it twice (in a distributed cache/database if we want to make the service scalable over multiple instances). Great, so let’s ask Stream Analytics to generate a GUID for us and attach it to the two messages… failed. ASA cannot generate GUIDs.
OK, not a problem, I will just get the current date and time which should be unique enough if we have time windows… failed. ASA doesn’t have a GETDATE() or any time function so we need to rely on some data in our message to generate a sort of “hash” or unique identifier for the message.
I choose to use the combination of the first event date and the last event date so it could precisely define our window.

Now our architecture is as highly available as possible (still with a chance of delaying the results in case of a ASA outage) so we should be able to sleep reasonably well knowing our service is (almost) always available (bombs/aliens apart).
